回上一頁
2005年, LHID2005 (2007年發行 100萬人)
2000年, LHID2000 (2002年發行 20萬人, 2009年發行 80萬人)
目的
全民健保資料庫的資料量相當龐大,若要提供所有的資料來做研究分析,則需相當大型的電腦系統,處理耗時且困難,容易造成錯誤偏差,並且十分不利隱私保護。解決的方式之一即是提供具代表性的抽樣資料,給使用者做研究分析。因此,建立以保險對象為基本抽樣單位的抽樣檔,收錄其歷年所有的就醫資料,並且持續追蹤,所成之歸人抽樣檔,將可供研究學者進行多類研究工作。
自2002年(91年)起本計畫提供20萬人承保抽樣歸人檔(LHID2000)供學界使用,研究人員取得承保抽樣歸人檔之後,可依其個別研究計畫需求,進行長期追蹤研究(longitudinal study)及任何時間點之橫斷面研究(cross-sectional study)。此LHID2000並於2009年增加提供80萬樣本人數資料(第5~20組),共發行100萬人之資料
由於LHID2000不包括2000年以後出生或新納保之保險對象,因此學者專家建議每間隔五年進行新一世代資料之抽樣,故我們在發行2005、2010年承保檔之時,再做一次歸人抽樣;惟因健保資料研究日見推廣,研究主題更為廣泛,研究學者提出抽樣歸人檔樣本數增加之需求,於是除重新抽樣外,更擴大抽樣人數為100萬人,擷取其所有就醫申報資料製作歸人檔。100萬人之承保抽樣歸人檔(LHID2005、LHID2010)可大幅提升進行具有統計檢定力(statistical power)之前瞻性研究(Prospective study)及回溯性研究(Retrospective study)之可能性。
1.
資料內容 :以2010年承保資料檔中「2010年在保者」隨機取100萬人,擷取其各年度就醫資料建置而成,並以每4萬人擷取一年度的就醫資料為一單位發行,每年更新。
2.
抽樣母群體
由中央健康保險署所提供的2010年承保資料檔以「身份證字號加上生日加上性別」歸人,可得27,378,403人之資料,作為資料母檔。在資料母檔中,剔除性別不詳者,選取在保者23,251,700人之資料為抽樣母群體。由於2010年承保資料檔所登錄的最後加保日為2010年12月31日,我們定義「2010在保者」為「2011年以前出生,2010年1月1日至2010年12月31日任何一日曾在保者」,並剔除年齡非0-120歲者
3.
抽樣方法:
自抽樣母群體隨機抽樣,取得100萬人樣本。隨機抽樣方法為將抽樣母群體23,251,700人賦予流水號,利用隨機值產生器(random number generator)產生至少100萬個隨機值(random number, 實得1,074,263個隨機值),取與100萬個隨機值相同的流水號,來隨機抽取所需的保險對象樣本,接著剔除身份證字號重複者(共24個),再補抽至得到100萬人樣本為止。
關於隨機值產生作業,我們係採用Oracle的DBMS_RANDOM套件來執行。DBMS_RANDOM套件提供一個內建的隨機值產生器(Oracle’s internal random number generator),可產生八位整數的隨機值。我們在1與23,251,700之間產生110萬個隨機值,剔除重複出現的隨機值(共25,346個)後,共得到1,074,263筆隨機值。
4.
承保抽樣歸人檔之構建
將隨機抽出的100萬人樣本,利用身份證字號(已加密)每4萬人為一組共25組,與健保資料庫串聯,擷取1996-2010年該100萬人在全民健保研究資料庫中所有就醫資料,即得100萬人承保抽樣歸人檔LHID2010,日後每年更新,加入這100萬人樣本新一年度的就醫資料。
所串接的就醫資料包含:門診處方及治療明細檔(CD)、門診處方醫令明細檔(OO)、住院醫療費用清單明細檔(DD)、住院醫療費用醫令明細檔(DO)、特約藥局處方及調劑明細檔(GD)、特約藥局處方調劑醫令明細檔(GO),以及原始承保資料。
5.
承保抽樣歸人檔代表性測試 :統計資料中年齡、性別、每年出生人數分佈,以及平均投保金額,比較100萬樣本與抽樣母群體之間是否有差異,同時並與內政部公佈之資料值比較,以分析100萬人樣本對抽樣母群體之代表性。由於承保抽樣歸人檔可以每四萬人為一組使用,我們亦選取其中一組四萬人之樣本,進行代表性分析,分析方式包括圖、表及統計假設檢定,詳如下列說明。
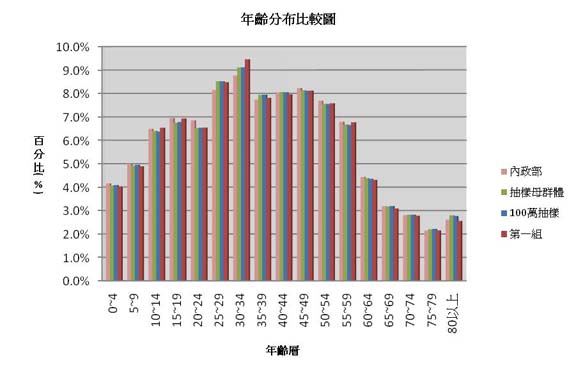
5-1.以每5歲(例:0-4歲)為一個年齡層分組,另80歲以上合併為一年齡層,統計各年齡層人數占人口總數 的百分比。比較100萬人樣本及其第1抽樣小組4萬人資料,與抽樣母群體,及內政部公佈之資料,各年齡層人數占人口總數的百分比之分布大致吻合。詳如圖一。
5-2.性別分布-
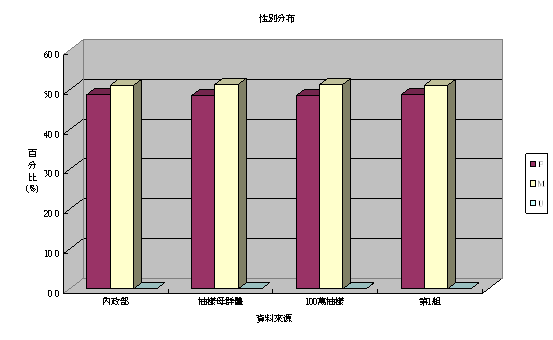
統計100萬人樣本得性別男:女比例為97:100,與抽樣母群體性別男:女比例相同;其第1抽樣小組4萬人資料性別男:女比例為96:100,比值亦極為接近,以卡方檢定100萬人樣本與抽樣母群體性別男:女比例無差異(χ2=0.067,
df=1,
p-value=0.796)。內政部公告之99年人口資料,性別男:女比例為101:100,與抽樣母群體不同(註)。詳如表一
表一、性別分佈表
資料別
性別比例
2010 年人口數
男 : 女
總計
男
女
抽樣母群體
97:100
23,251,700
11,452,740
11,798,960
100 萬抽樣
97:100
1,000,000
492,423
507,577
第 1 組四萬人
96:100
40,000
19,627
20,373
內政部人口統計
101:100
23,162,123
11,635,225
11,526,898
5-4.投保費用--統計100萬人樣本及其第1抽樣小組4萬人資料平均投保金額,以normal test分析,其與抽樣母群體之差異均在5%顯著水準以下。
註: 全民健康保險研究資料庫不含在軍方單位投保者之資料(見100-9版譯碼簿A-58頁之承保檔說明)。
6.
隨機值產生作業的程式如下:
declare
lv_seed_num number := 1585131;
lv_random_num number ;
lv_loop_num number;
ct number := 1;
samp_num number := 1100000;
BEGIN
DBMS_RANDOM.INITIALIZE(lv_seed_num);
FOR lv_loop_num IN 1..1500000000 LOOP
lv_random_num := DBMS_RANDOM.RANDOM;
if ((lv_random_num < 23251701) and (lv_random_num > 0) ) then
INSERT INTO &&1 (RND, SEQ) VALUES (lv_random_num, ct);
commit;
ct := ct + 1;
end if;
exit when ct = samp_num + 1;
END LOOP;
DBMS_RANDOM.TERMINATE;
END;
1.
資料內容 :以2005年承保資料檔中「2005年在保者」隨機取100萬人,擷取其各年度就醫資料建置而成,並以每4萬人擷取一年度的就醫資料為一單位發行,每年更新。
2.
抽樣母群體
由中央健康保險署所提供的2005年承保資料檔以「身份證字號加上生日加上性別」歸人,可得25,678,998人之資料,作為資料母檔。在資料母檔中,選取在保者22,717,053人之資料為抽樣母群體。由於2005年承保資料檔所登錄的最後異動日為2006年1月1日,我們定義「在保者」為「2006年以前出生,2005年1月1日至2006年1月1日任何一日曾在保者」,並剔除年齡非0-120歲者。
3.
抽樣方法:
自抽樣母群體隨機抽樣,取得100萬人樣本。隨機抽樣方法為將抽樣母群體22,717,053人賦予流水號,利用亂數產生器(random
number generator)產生至少100萬個亂數(random number, 實得1,073,891個亂數),取與100萬個亂數值相同的流水號,來隨機抽取所需的保險對象樣本,接著剔除身份證字號重複者(共64個),再補抽至得到100萬人樣本為止。
關於亂數產生作業,我們係採用Oracle的DBMS_RANDOM套件來執行。DBMS_RANDOM套件提供一個內建的亂數產生器(Oracle’s
internal random number generator),可產生八位整數的亂數。我們在1與22,717,053之間產生110萬個亂數,剔除重複出現的亂數(共25677個)後,共得到1,073,891筆亂數。
4.
承保抽樣歸人檔之構建
將隨機抽出的100萬人樣本,利用身份證字號(已加密)每4萬人為一組共25組,與健保資料庫串聯,擷取1996-2006年該100萬人在全民健保研究資料庫中所有就醫資料,即得100萬人承保抽樣歸人檔LHID2005,日後每年更新,加入這100萬人樣本新一年度的就醫資料。
所串接的就醫資料包含:門診處方及治療明細檔(CD)、門診處方醫令明細檔(OO)、住院醫療費用清單明細檔(DD)、住院醫療費用醫令明細檔(DO)、特約藥局處方及調劑明細檔(GD)、特約藥局處方調劑醫令明細檔(GO),以及原始承保資料。
5.
承保抽樣歸人檔代表性測試 :統計資料中年齡、性別、每年出生人數分佈,以及平均投保金額,比較100萬樣本與抽樣母群體之間是否有差異,同時並與內政部公佈之資料值比較,以分析100萬人樣本對抽樣母群體之代表性。由於承保抽樣歸人檔可以每四萬人為一組使用,我們亦選取其中一組四萬人之樣本,進行代表性分析,分析方式包括圖、表及統計假設檢定,詳如下列說明。
5-1.年齡分布-以每5歲(例:0-4歲)為一個年齡層分組,另80歲以上合併為一年齡層,統計各年齡層人數占人口總數
的百分比。比較100萬人樣本及其第1抽樣小組4萬人資料,與抽樣母群體,及內政部公佈之資料,各年齡層人數占人口總數的百分比之分布大致吻合。詳如圖一。
5-2.性別分布- 統計100萬人樣本得性別男:女比例為98:100,與抽樣母群體性別男:女比例相同;其第1抽樣小組4萬人資料性別男:女比例為99:100,比值亦極為接近,以卡方檢定100萬人樣本與抽樣母群體性別男:女比例無差異(χ2=0.008, df=1,p-value=0.931)。內政部公告之94年人口資料,性別男:女比例為103:100,與抽樣母群體不同。詳如表一。
表一、性別分佈表
資料別
性別比例
2005 年人口數
男 : 女
總計
男
女
性別不詳
抽樣母群體
98 : 100
22,717,053
11,262,470
11,454,582
1
100 萬抽樣
98 : 100
1,000,000
495,816
504,184
0
第 1 組四萬人
99 : 100
40,000
19,877
20,123
0
內政部人口統計
103 : 100
22,770,383
11,562,440
11,207,943
0
5-3.每年出生人數分布--統計100萬人樣本及其第1抽樣小組4萬人資料每年出生人數分布,以卡方分析,其與抽樣母群體之差異均在5%顯著水準以下。
5-4.投保費用--統計100萬人樣本及其第1抽樣小組4萬人資料平均投保金額,以normal test分析,其與抽樣母群體之差異均在5%顯著水準以下。
6.
隨機值產生作業的程式如下:
declare
lv_seed_num number := 1449604;
lv_random_num number ;
lv_loop_num number;
ct number := 1;
samp_num number := 1100000;
BEGIN
DBMS_RANDOM.INITIALIZE(lv_seed_num);
FOR lv_loop_num IN 1..1500000000 LOOP
lv_random_num := DBMS_RANDOM.RANDOM;
if ((lv_random_num < 22717054) and (lv_random_num > 0) ) then
INSERT INTO &&1 (RND, SEQ) VALUES (lv_random_num, ct);
commit;
ct := ct + 1;
end if;
exit when ct = samp_num + 1;
END LOOP;
DBMS_RANDOM.TERMINATE;
END;
1.
資料內容 :自2000年承保資料檔中隨機選取100萬人,擷取其各年度所有就醫資料建置而成,並以每5萬人擷取一年度的就醫資料為一單位發行,每年更新。
2.
抽樣母群體
以中央健康保險署所提供的2000年承保資料檔保險對象為抽樣母群體。2000年承保資料檔包含中央健康保險署開辦起至89年12月底止,約共有5,806萬筆保險對象累積性的歷史資料,隨著保險對象不同身份別或工作單位的異動而有轉出、轉入的紀錄,皆保存於承保檔之中。將重複的「身份證字號」去除後,約有2,372萬筆資料。
3.
抽樣方法: 以2000年承保檔的保險對象為母群體,進行隨機抽樣。
我們根據承保檔的「身份證號(已加密)加上生日加上性別」來定義一個保險對象的身份,而得23,753,407人,作為母群體。觀察母群體,存在有相同的身份證號(簡稱ID)被不同的兩人共同持有之情形 (即ID同、但對應之「生日加上性別」不同)。2000年母群體中,此類共用ID比率約千分之一,詳見附表一 。
抽樣方法為將母群體的每個保險對象賦予流水號,再從這些不同保險對象隨機抽樣。隨機抽樣是以亂數產生函數(random number function)產生隨機亂數(random number),將不重複的亂數與承保檔母群體保險對象的流水號進行聯結,來隨機抽取所需的保險對象樣本。
關於亂數產生作業,我們採用Sun Work Shop C 5.0的函數功能a來產生亂數。該函數是根據Knuth(1981)及Park and Miller(1998)的方法(詳見參考文獻),採用linear congruential random number generation的技巧撰寫而成b。該產生方式可以取出數值在1與2,147,483,646之間的亂數。我們運用程式從設定的取值範圍1與23,753,407之間取出110萬筆亂數值,再從這110萬筆亂數值中剔除重複出現的亂數值(約2~3萬筆)後,最後從剩下的值中分20次,每次依序取出5萬筆資料為一組,一共得到100萬筆亂數,自母群體中選取與100萬個亂數值相同的流水號,來隨機抽取所需的保險對象樣本。檢測100萬人及各抽樣組樣本之共用ID比率均約千分之二,詳見附表二 。
4.
承保歸人抽樣檔之構建: 承保資料檔保險對象與健保資料庫串聯。
將隨機抽出的100萬保險對象ID與健保資料庫串聯,擷取該100萬人所有就醫資料,即得100萬人承保抽樣歸人檔。利用保險對象的身份證字號每五萬人為一組共二十組,與健保資料庫進行歷年所有就醫資料的聯結,所串接的資料包含:門診處方及治療明細檔(CD)、門診處方醫令明細檔(OO)、住院醫療費用清單明細檔(DD)、住院醫療費用醫令明細檔(DO)、特約藥局處方及調劑明細檔(GD)、特約藥局處方調劑醫令明細檔(GO),以及這些保險對象的原始承保資料,並每年更新。其中第1~4組20萬人的資料於2002年發行,其餘80萬人(第5~20組)的資料於2009年發行。
5.
承保抽樣歸人檔代表性測試: 統計資料中年齡、性別、每年出生人數分佈,以及平均投保金額,比較100萬樣本ID與抽樣母群體之間是否有差異,同時並與內政部公佈之資料值比較,以分析100萬人樣本對母群體之代表性。由於承保抽樣歸人檔可以每五萬人為一組使用,我們亦選取其中一組五萬人之樣本,進行代表性分析,分析方式包括圖、表及統計假設檢定,詳如下列說明。
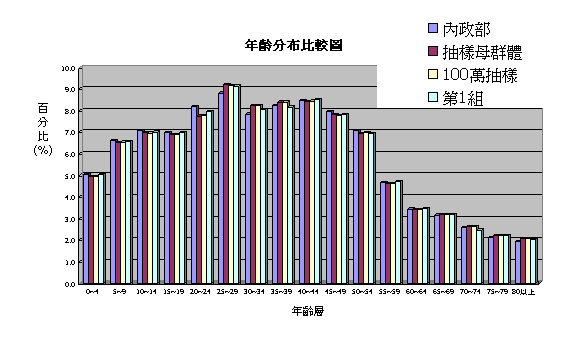
5-1年齡分布-以每5歲(例:0-4歲)為一個年齡層分組,另100歲以上合併為一年齡層,統計各年齡層人數占人口總數 的百分比。比較100萬人樣本及其第1抽樣小組5萬人資料,與抽樣母群體,及內政部公佈之資料,各年齡層人數占人口總數的百分比之分布大致吻合。
5-2性別分布- 統計100萬人樣本得性別男:女比例為106:100,與抽樣母群體性別男:女比例相同(以前四組20萬人進行卡方檢定結果亦同:χ2=1.74, df=1, p-value=0.187);其第1抽樣小組5萬人資料性別男:女比例為105:100,比值亦極為接近。內政部公告之89年人口資料,性別男:女比例為105:100,與第1組比值相同,與抽樣母群體、100萬人樣本之性別比值亦極為接近。若比較男、女人數占人口總數的百分比,則100萬人及其第1組樣本、抽樣母群體,及內政部公佈之資料,均為女性占49%、男性占51%。
5-3 每年出生人數分布--統計100萬人樣本及其第1抽樣小組5萬人資料的每年出生人數分布,以卡方分析,其與抽樣母群體之差異均在5%顯著水準以下。
5-4.投保費用--統計100萬人樣本及其第1抽樣小組5萬人資料平均投保金額,以normal test分析,其與抽樣母群體之差異均在5%顯著水準以下。
參考文獻
1.
Donald E. Knuth, Seminumerical Algorithms, 1981, Addison-Wesley。
2.
S.K. Park and Miller, “Random Number Generators: Good Ones are Hard to Find”, Communications of the ACM, October 1988, pp.1192-1201。
程式說明
a.
lcran_last = (LCRAN_MULTIPLIER * lcran_last) % LCRAN_MODULUS;
return scale * (lcran_last + offset) ;
b.
程式如下:
#include <sunmath.h>
#define LCRAN_MULTIPLIER 16807
#define LCRAN_MODULUS 2147483647L
main() {
int x[1],n=1,lb=1,ub=23753407;
int i;
for (i=0;i<110000;i++) {
i_lcrans_(x,&n,&lb,&ub); //從1到23,753,407取出1,100,000個數值
printf("%d\n",x[0]);
}
}
附表一:2000年承保檔之共用ID比率:
資料檔
總 ID 數
(A)
以「 ID+生日 + 性別」
歸人數 (B)
共用ID
(B) - (A)
共用ID (%)
(B-A)/B
2000 年 承保檔
23,725,083
23,753,407
28,324
0.12%
附表二: 2000年承保抽樣歸人檔之共用ID 比率 :
資料檔
總 ID 數
(A)
以「 ID+ 生日 + 性別」
歸人數 (B)
共用ID
(B) - (A)
共用ID (%)
(B-A)/B
100 萬抽樣 ID
1,000,000
1,002,420
2,420
0.24%
第 1 組 (2002 年發行 )
50,000
50,109
109
0.22%
第 2 組 (2002 年發行 )
50,000
50,143
143
0.29%
第 3 組 (2002 年發行 )
50,000
50,122
122
0.24%
第 4 組 (2002 年發行 )
50,000
50,147
147
0.29%
第 5 組 (2009 年發行 )
50,000
50,108
108
0.22%
第 6 組 (2009 年發行 )
50,000
50,147
147
0.29%
第 7 組 (2009 年發行 )
50,000
50,099
99
0.20%
第 8 組 (2009 年發行 )
50,000
50,119
119
0.24%
第 9 組 (2009 年發行 )
50,000
50,111
111
0.22%
第 10 組 (2009 年發行 )
50,000
50,103
103
0.21%
第 11 組 (2009 年發行 )
50,000
50,116
116
0.23%
第 12 組 (2009 年發行 )
50,000
50,121
121
0.24%
第 13 組 (2009 年發行 )
50,000
50,127
127
0.25%
第 14 組 (2009 年發行 )
50,000
50,141
141
0.28%
第 15 組 (2009 年發行 )
50,000
50,127
127
0.25%
第 16 組 (2009 年發行 )
50,000
50,112
112
0.22%
第 17 組 (2009 年發行 )
50,000
50,113
113
0.23%
第 18 組 (2009 年發行 )
50,000
50,106
106
0.21%
第 19 組 (2009 年發行 )
50,000
50,134
134
0.27%
第 20 組 (2009 年發行 )
50,000
50,115
115
0.23%
回上一頁